Perché i log sono il primo posto dove guardare
Quando qualcosa si rompe su un sistema Linux, i log sono quasi sempre la prima risposta. Eppure molti amministratori li consultano solo come ultima risorsa, quando ormai il danno è fatto. I log raccontano cosa sta facendo il sistema adesso, cosa ha fatto ieri notte, e cosa esattamente è andato storto alle 3:00 di questa mattina. Imparare a leggerli, cercarli e gestirli è una delle competenze fondamentali di ogni sysadmin.
Questa guida copre i file di log che ogni amministratore Linux dovrebbe conoscere, gli strumenti per cercarli in modo efficiente, e come evitare che crescano fino a riempire il disco.
Dove vivono i log su Linux
La maggior parte dei file di log si trova sotto /var/log/. Alcuni sono testo semplice, altri sono binari e richiedono strumenti dedicati per essere letti. Ecco i più importanti:
/var/log/syslog(Debian/Ubuntu) o/var/log/messages(RHEL/CentOS/Fedora) — messaggi generali di sistema da kernel e servizi./var/log/auth.log(Debian/Ubuntu) o/var/log/secure(RHEL/CentOS/Fedora) — tentativi di autenticazione, uso di sudo, accessi SSH./var/log/kern.log— messaggi specifici del kernel. Utile per problemi hardware e driver./var/log/dmesg— output del kernel ring buffer dal boot. Accessibile anche tramite il comandodmesg./var/log/dpkg.log— cronologia di installazione, rimozione e aggiornamento pacchetti su sistemi Debian./var/log/dnf.logo/var/log/yum.log— equivalente per Fedora/RHEL./var/log/apache2/o/var/log/httpd/— log di accesso ed errore di Apache./var/log/nginx/— log di accesso ed errore di Nginx./var/log/mysql/— log degli errori MySQL./var/log/crono/var/log/cron.log— cronologia di esecuzione dei cron job.
Sui sistemi moderni basati su systemd, molti di questi log tradizionali sono affiancati o sostituiti dal journal di systemd. Ne parliamo nella sezione dedicata a journalctl.
Lettura di base: tail, less e cat
Per i file di testo semplice, gli strumenti classici funzionano benissimo.
Visualizzare la coda del log
tail /var/log/syslogSeguire un log in tempo reale
tail -f /var/log/syslogUtile quando si sta riproducendo un problema in diretta. Per seguire più file contemporaneamente:
tail -f /var/log/syslog /var/log/auth.logSfogliare il log completo con paginazione
less /var/log/syslogAll’interno di less: G salta alla fine, g torna all’inizio, /pattern cerca un termine. Molto più veloce di quanto sembri.
Ricerca nei log con grep
Quando un log cresce oltre qualche MB, scorrere manualmente diventa inutile. grep è lo strumento principale per filtrare le righe rilevanti.
Trovare tutti i fallimenti di autenticazione SSH
grep "Failed password" /var/log/auth.logRicerca case-insensitive
grep -i "error" /var/log/syslogMostrare il contesto intorno a ogni match (3 righe prima e dopo)
grep -C 3 "Out of memory" /var/log/syslogRicerca ricorsiva in una directory
grep -r "connection refused" /var/log/nginx/Contare quante volte appare un pattern
grep -c "Failed password" /var/log/auth.logFiltrare per una data specifica
grep "^May 21" /var/log/syslogCombinare tail e grep per cercare solo nelle righe recenti
tail -n 500 /var/log/syslog | grep "error"Il journal di systemd: journalctl
Su qualsiasi distro moderna basata su systemd, journalctl è spesso più potente dei file di log tradizionali. Il journal raccoglie output da tutti i servizi, dal kernel e dal processo di boot in un formato binario strutturato e interrogabile.
Comandi essenziali di journalctl
# Tutte le voci del journal (dalla più vecchia)
journalctl
# Dal più recente al più vecchio
journalctl -r
# Seguire il journal in tempo reale (come tail -f)
journalctl -f
# Solo i messaggi del kernel
journalctl -k
# Log di un servizio specifico
journalctl -u nginx
journalctl -u sshd
# Solo dal boot corrente
journalctl -b
# Dal boot precedente (utile dopo un crash o riavvio imprevisto)
journalctl -b -1
# Solo errori e livelli superiori (emergency, alert, critical, error)
journalctl -p err
# Filtro per intervallo di tempo
journalctl --since "2026-05-21 08:00:00" --until "2026-05-21 09:00:00"
# Oppure con tempo relativo
journalctl --since "1 hour ago"
# Output compatto senza pager, utile per piping
journalctl -u sshd -o short --no-pager | tail -50Il flag --no-pager disabilita l’apertura automatica di less e restituisce l’output direttamente al terminale. Indispensabile quando si vuole fare pipe verso grep o altri strumenti.
Analisi dei log di autenticazione SSH
Il log di autenticazione è uno dei più importanti su qualsiasi server esposto a internet. Se il server ha un IP pubblico, ci saranno tentativi di brute-force costanti. Ecco come analizzarli.
Vedere i fallimenti SSH recenti
# Su Debian/Ubuntu
grep "Failed password" /var/log/auth.log | tail -20
# Su RHEL/CentOS/Fedora
grep "Failed password" /var/log/secure | tail -20
# Su qualsiasi sistema systemd
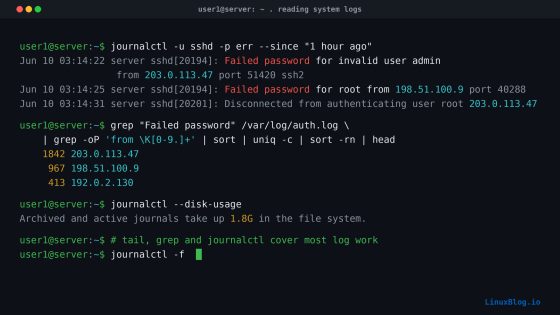
journalctl -u sshd | grep "Failed password" | tail -20Trovare gli IP che attaccano di più
grep "Failed password" /var/log/auth.log \
| grep -oP 'from \K[0-9.]+' \
| sort | uniq -c | sort -rn | head -10Questo one-liner estrae l’IP sorgente da ogni riga di login fallito, conta le occorrenze e le ordina per frequenza decrescente. L’anchor sulla parola from mantiene il match corretto indipendentemente dal formato esatto della riga (con o senza “invalid user”). L’output di questo comando è spesso sufficiente a motivare l’installazione immediata di fail2ban.
Log del kernel e del boot con dmesg
Il comando dmesg legge dal kernel ring buffer ed è particolarmente utile per diagnosticare problemi hardware, driver e dischi.
# Tutti i messaggi kernel
dmesg
# Con timestamp leggibili
dmesg -T
# Solo errori e warning
dmesg -T --level=err,warn
# Cercare errori disco
dmesg -T | grep -i "error\|fail\|reset"Se un disco sta cedendo, si vedranno righe che menzionano il nome del device (sda, nvme0, ecc.) con parole come I/O error o hard resetting link. Non vanno ignorate.
Gestione della rotazione: logrotate
I log mangiano disco se non vengono gestiti. Su quasi tutti i sistemi Linux, logrotate si occupa di questo automaticamente: comprime e ruota i file di log secondo una schedulazione configurabile.
Il file di configurazione principale è /etc/logrotate.conf, mentre le configurazioni per singola applicazione si trovano sotto /etc/logrotate.d/.
Un esempio tipico per Nginx:
/var/log/nginx/*.log {
daily
missingok
rotate 14
compress
delaycompress
notifempty
create 0640 www-data adm
sharedscripts
postrotate
[ -f /var/run/nginx.pid ] && kill -USR1 `cat /var/run/nginx.pid`
endscript
}Le direttive principali da conoscere:
daily / weekly / monthly— frequenza di rotazione.rotate 14— quanti file vecchi conservare prima di cancellare.compress— comprime i log ruotati con gzip.delaycompress— non comprime il log ruotato più di recente (utile per applicazioni che tengono il file aperto brevemente dopo la rotazione).missingok— non genera errore se il file di log non esiste.postrotate— esegue un comando dopo la rotazione, tipicamente per segnalare all’applicazione di riaprire il file di log.
Test e debug di logrotate
# Simulare la rotazione senza eseguirla davvero
sudo logrotate --debug /etc/logrotate.conf
# Forzare la rotazione immediatamente (utile per test)
sudo logrotate --force /etc/logrotate.d/nginxGestione della dimensione del journal systemd
Anche il journal di systemd può crescere molto se non monitorato. Verificare l’utilizzo disco e limitarlo:
# Verificare lo spazio occupato dal journal
journalctl --disk-usage
# Ridurre il journal a un massimo di 500 MB
sudo journalctl --vacuum-size=500M
# Mantenere solo le voci degli ultimi 30 giorni
sudo journalctl --vacuum-time=30dPer impostare un limite permanente, modificare /etc/systemd/journald.conf:
[Journal]
SystemMaxUse=500M
MaxRetentionSec=1monthDopo la modifica, riavviare il servizio: sudo systemctl restart systemd-journald.
Un workflow pratico per il troubleshooting
Quando si affronta un problema su un server Linux, un approccio sistematico ai log risparmia tempo. Partire da journalctl -p err -b per vedere tutti gli errori del boot corrente, poi restringere con journalctl -u nome-servizio --since "30 min ago" per il servizio specifico. Se il problema è comparso dopo un riavvio, journalctl -b -1 mostra i log del boot precedente. Per problemi hardware, dmesg -T --level=err,warn è spesso la risposta più rapida.
I log su Linux non sono una last resort: sono la prima e più affidabile fonte di verità su cosa sta succedendo nel sistema.
Fonte originale: LinuxBlog.io — Linux Log Files: Guide to Reading, Searching, and Managing Logs di Hayden James.